
Generativ kunstig intelligens og store språkmodeller i høyere utdanning
Kunstig intelligens (KI) og Store Språkmodeller (Large Language Model, LLM) er de siste mye omtalte buzz-ordene. Generativ kunstig intelligens (gen KI), refererer til en klasse av KI-modeller som er i stand til å generere eller skape nytt innhold, som tekst, bilder eller lyd, som ligner på dataene de ble trent på [1, 2]. LLM er en type gen KI spesielt designet for å forstå og etterligne menneskelig språk. Dette kan potensielt gi mange nye hjelpemidler for studenter, forskere og også klinikere. Brukt riktig kan KI være et effektiviserende hjelpemiddel. Tilgjengeliggjøringen av KI kan potensielt få stor betydning for både forskning og høyere utdanning.
Hva er kunstig intelligens
En organisasjon (OpenAI) som har som mål å fremme og utvikle KI og maskinlæring (ML) til beste for menneskeheten ble grunnlagt i desember 2015 av blant annet Elon Musk. Den første versjonen av deres samtalebaserte KI modell (GPT-1,Tabell 1) ble lansert i juni 2020. Denne modellen markerte begynnelsen på ChatGPT-serien, som siden har utviklet seg med påfølgende versjoner som GPT-2 til GPT-4. Siste oppdatering ble integrert i ChatGPT-produktet i mars 2023.Det finnes mange eksempler på generativ KI. Andre eksempler inkluderer StyleGAN, DeepDream, Pix2pix, WaveGen, og denne listen utvides stadig. ChatGPT ble offisielt lansert for offentligheten den 30. november 2022. Det var første gang en GPT-basert samtale-KI ble gjort bredt tilgjengelig for daglig brukere via et nettgrensesnitt. Lanseringen fikk raskt stor oppmerksomhet, og millioner av brukere begynte å samhandle med den, noe som utløste enorm interesse for KI-drevne samtalemodeller. Disse er designet for å delta i samtaler på naturlig språk med brukere, og gi svar som er kontekstuelt relevante og sammenhengende. De kan forstå og generere menneskelignende tekst på et bredt spekter av emner og oppgaver, noe som gjør dem egnet for ulike bruksområder som kundeservice, språkopplæring, støtte for kreativ skriving og mer. Den er trent på et mangfoldig datasett som inneholder en stor mengde tekst fra internett, noe som gjør at den kan fange opp og etterlikne mange nyanser av menneskelig språk og samtale.
Et KI-drevet akademisk søkeverktøy som bruker ML og naturlig språkprosessering (NLP) for å analysere tekst og anbefale relevante forskningsartikler ble utviklet av et norsk oppstartsselskap (Keenious AS), som har base i Tromsø, Norge. Selskapet ble grunnlagt i 2019 av et team av forskere og ingeniører med mål om å forbedre akademisk forskning ved hjelp av KI. Det finnes flere ander tilsvarende verktøy. Disser er ikke en LLM som ChatGPT, men analyserer en gitt tekst og søker etter relevante akademiske kilder. Dette effektiviserer litteratursøk. Keenious er tilgjengelig som en plugin for Microsoft Word. Det integreres direkte i Word for å hjelpe brukere med å finne relevante akademiske artikler mens de skriver. Selv om både Keenious og ChatGPT bruker KI, er Keenious spesialisert for akademisk forskning, mens LLM-er er mer generelle språkmodeller.
Copilot i Microsoft Edge er en innebygd KI-assistent som bruker Microsofts teknologi og Bing AI for å forbedre nettleseropplevelsen. Den hjelper med oppgaver som tekstskriving, oppsummering av artikler, søk med kontekst, og produktivitetsverktøy som oppgavestyring og innholdsoppretting. Copilot er integrert i sidepanelet og fungerer som en personlig assistent for både arbeid og daglige aktiviteter, og tilbyr smartere og mer effektive løsninger sammenlignet med tradisjonelle verktøy.
Hvordan virker LLM?
En LLM fungerer ved å utnytte en dyp lærings-arkitektur kalt transformer. Her er en forenklet forklaring på hvordan den opererer:
Inndatakoding: Når du gir en LLM en ledetekst eller en oppfordring (prompt på engelsk), koder den først inn inndataene ved hjelp av tokenisering (oppdeling), og konverterer ord eller delord til numeriske representasjoner. Bearbeiding med transformerlag: De kodede inndataene blir deretter bearbeidet gjennom flere lag med transformerblokker.
Generering av utdata: Etter å ha bearbeidet inndataene gjennom transformerlagene, genererer modellen én utdatatoken om gangen. Den forutsier den mest sannsynlige token som skal komme etter den forrige basert på konteksten gitt av inndataene og dens innlærte kunnskap fra forhåndstreningen.
Gjentakelse og diversifisering: Under genereringsprosessen kan modellen noen ganger gjenta seg selv eller produsere generiske svar.
Scoring og utvalg: Når modellen genererer flere mulige fullføringer, tildeles hver fullføring en sannsynlighetsscore basert på hvor sannsynlig den er i henhold til modellens parametere.
Finjustering: LLM-er blir ofte finjustert på spesifikke datasett eller oppgaver for å tilpasse dem til bestemte bruksområder, og dermed forbedre ytelsen og relevansen deres for spesifikke kontekster.
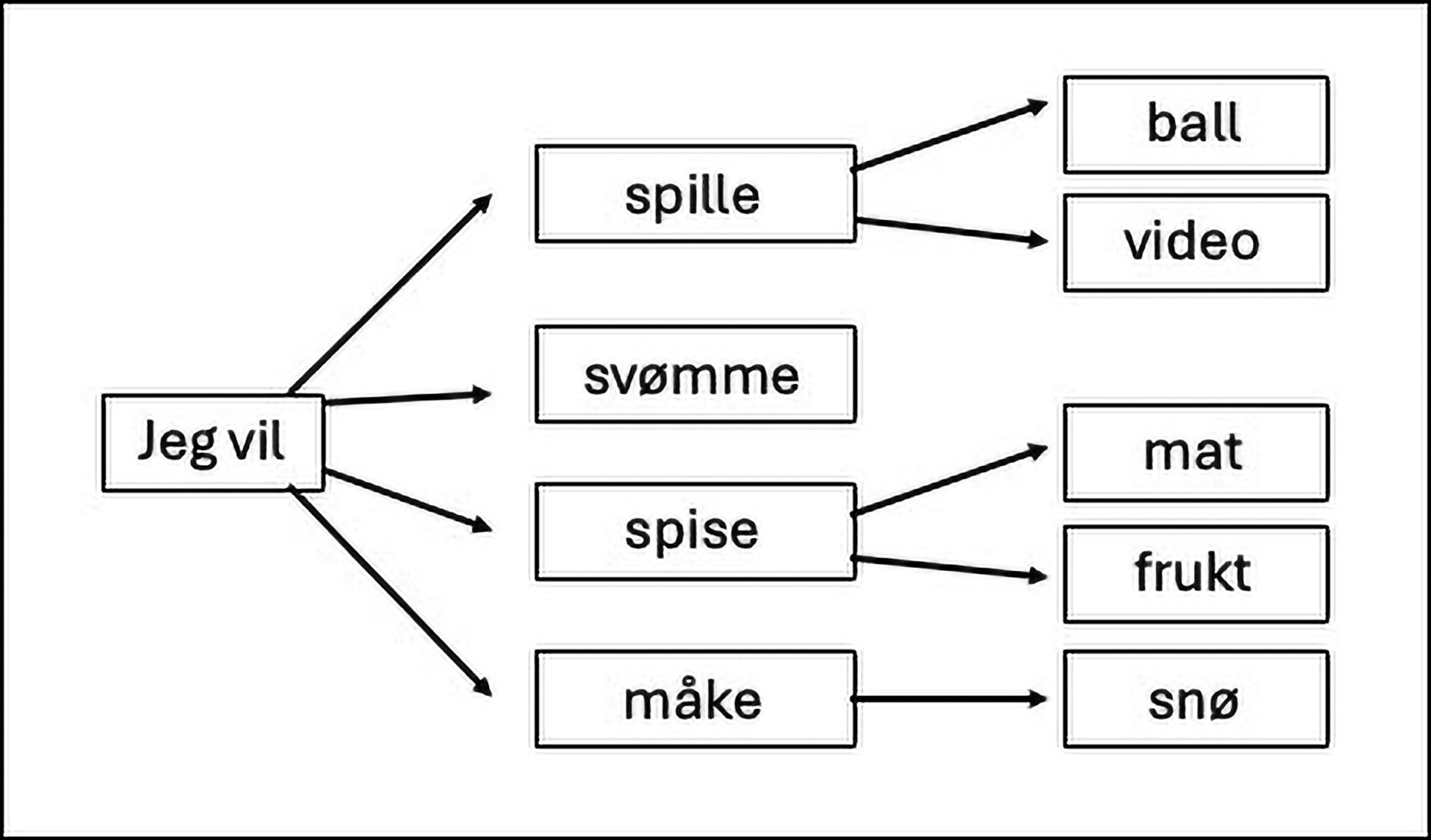
Figur 1. Flytskjema viser hvordan LLM generere sannsynlig ord. Jeg vil svømme for eksempel har ingen fortsettelse, men jeg vil spille genererer ord som ball eller video.
Kunstig intelligens og høyere utdanning
KI har allerede gitt Universitets- og høyskolesektoren i Norge mye hodebry. Noen institusjoner gikk raskt ut med forbud, mens andre heller forsøkt å gi studentene en trygg arena for bruk av KI. Samtlige institusjoner har strevd med å gi tydelige og gode retningslinjer for studentene. For ansatte har situasjonen vært annerledes og litt mer «fritt frem» politikk. Det er flere grunner til at dette har vært vanskelig. For det første, har de som skulle eller burde laget retningslinjer ikke hatt nok kompetanse på området. For det andre, er det vanskelig å lage retningslinjer for noe som er konstant i endring. Resultatet blir dermed at noen studenter er kjappe med å teste ut og skaffe seg kompetanse på dette området, mens mange ikke tør benytte hjelpemidlene av frykt for å felles for fusk.
UiBchat er en tjeneste tilgjengelig fra chat.uib.no tilsvarende ChatGPT som gjøres tilgjengelig for UiBs studenter og ansatte. Det gir et grensesnitt der du kan ha en samtale med en robotassistent drevet av den gen KI-modellen GPT-4. I denne versjonen av tjenesten lagres ingen data. Chat-logger lagres kun i brukerens nettleser og enhet. UiBchat er godkjent for gule og grønne data. Gule data representerer ofte begrenset eller sensitiv informasjon som krever forsiktighet ved deling, men som ikke er like konfidensielle som "røde data". Eksempler kan være interne e-poster, prosjektfiler eller dokumenter som inneholder ikke-kritisk bedriftsinformasjon. Grønne data: Refererer til offentlig eller lavrisikoinformasjon som kan deles fritt uten betydelige sikkerhets- eller personvernhensyn. Eksempler kan inkludere markedsføringsmateriell, offentlige rapporter eller generell kontaktinformasjon. Denne godkjenningen sikrer at plattformen oppfyller nødvendige sikkerhets- og personvernkrav for håndtering av ulike typer data innenfor universitetet eller organisasjonen.
En undersøkelse utført i april 2024 på kull 3 tannlegestudenter viste imidlertid at studentene ikke var så kjent med KI eller LLM som forventet. For eksempel rapporterte kun en tredjedel av kull 3 tannlegestudentene at de hadde noen erfaring med ChatGPT og/eller annen LLM. Ingen av studentene var klar over UiBchat (Figur 2).
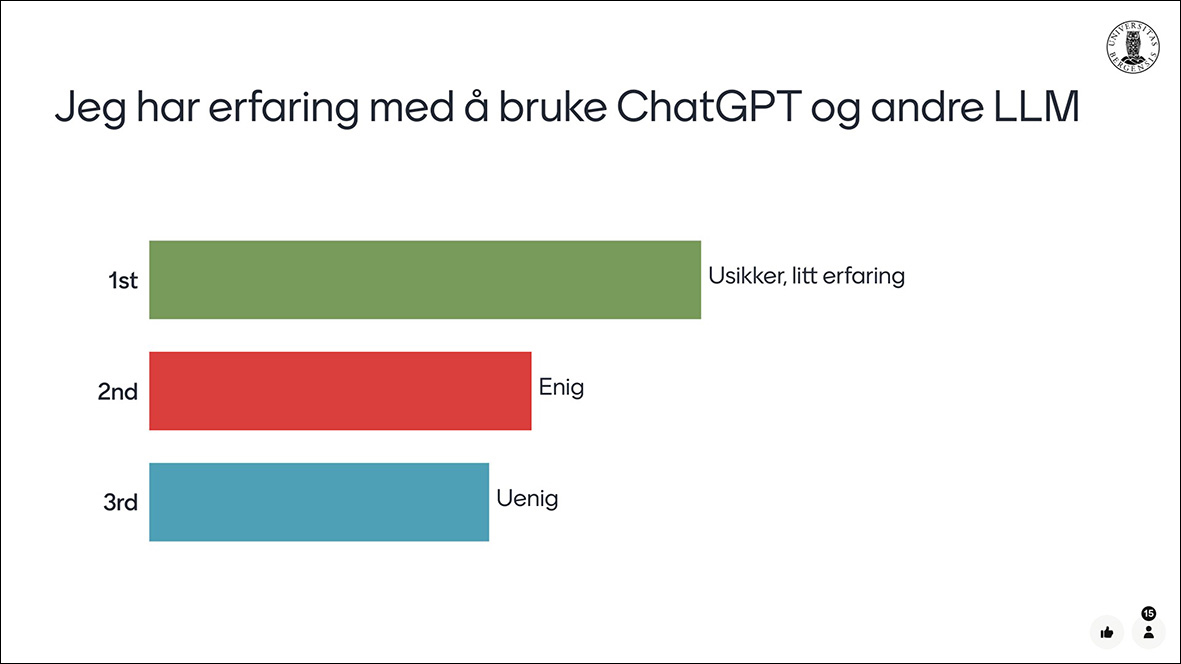
Figur 2: Fordelingen av tannlegestudentenes svar på spørsmålet «Jeg har erfaring med å bruke ChatGPT og andre LLM».
LLM fungerer veldig bra på engelsk. Når det gjelder andre språk, avhengig av bruken, kan det gi begrensede svar. Språkskjevhet oppstår fordi KI-modeller ofte trenes på datasett dominert av engelskspråklig informasjon. Dette betyr ofte at en modell vil prestere bedre på en engelskspråklig oppgave enn den vil på andre språk, og utilsiktet begrenser nytten for folk som ikke har engelsk som førstespråk.
Interessant nok, når du stilleret spørsmål på norsk, for eksempel, hva er suksessraten for revisjonsbehandling i endodonti, får du følgende referanser:
[3] Hvorfor blir ikke alltid rotfylling vellykket? - Institutt for klinisk odontologi (uio.no)
[4] Når bør rotfyllingen revideres? | Den norske tannlegeforenings Tidende (tannlegetidende.no)
Når du stiller det samme spørsmålet på engelsk, «What is the success rate for retreatment in Endodontics?» oppgis disse referansene i stedet.
[6] Dental Update - Theoretical considerations for root canal re-treatment (dental-update.co.uk)
Surgical endodontic retreatment | Periodontal and Implant Research (springer.com)
En av disse referansene handler ikke om revisjonsbehandling da den omhandler endodontisk kirurgi. Imidlertid blir endodontisk kirurgi ofte referert til som "surgical retreatment" på engelsk, mens revisjonsbehandling kalles "non-surgical retreatment". Så denne referansen er ikke langt fra virkeligheten. Imidlertid har LLM vært kjent for å "hallusinere" eller gi ikke-eksisterende referanser som bøker og artikler. Dette skjer fordi modellen er trent opp til å tilfredsstille deg og dine spørsmål. Om den ikke finner et svar, vil den dikte opp det som virker mest troverdig for å i hvert fall levere noe. Om du er misfornøyd med svaret, vil den som regel beklage seg og komme opp med en nytt alternativ.
Det er mange programmer som kan tegne bilder eller illustrasjoner på bestilling Du kan til og med velge hva slags illustrasjon du vil ha og hvilken stil og egenskaper (Figur 3-5).
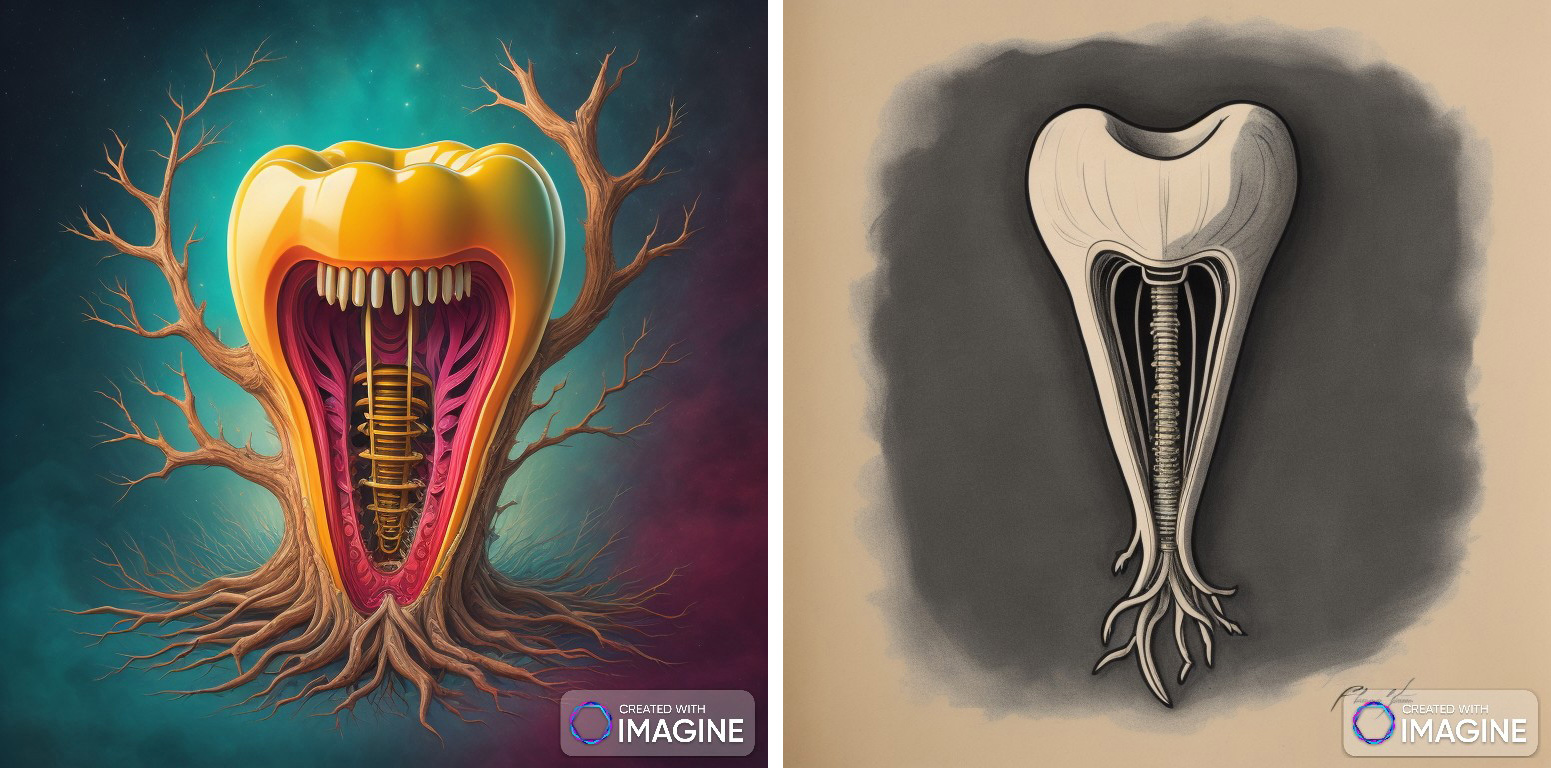
Figur 3A og B. Viser to ulike bilder laget av et gratis KI program (Imagine, https://www.imagine.art/dashboard/image) etter oppfordringen «draw me a root canal».
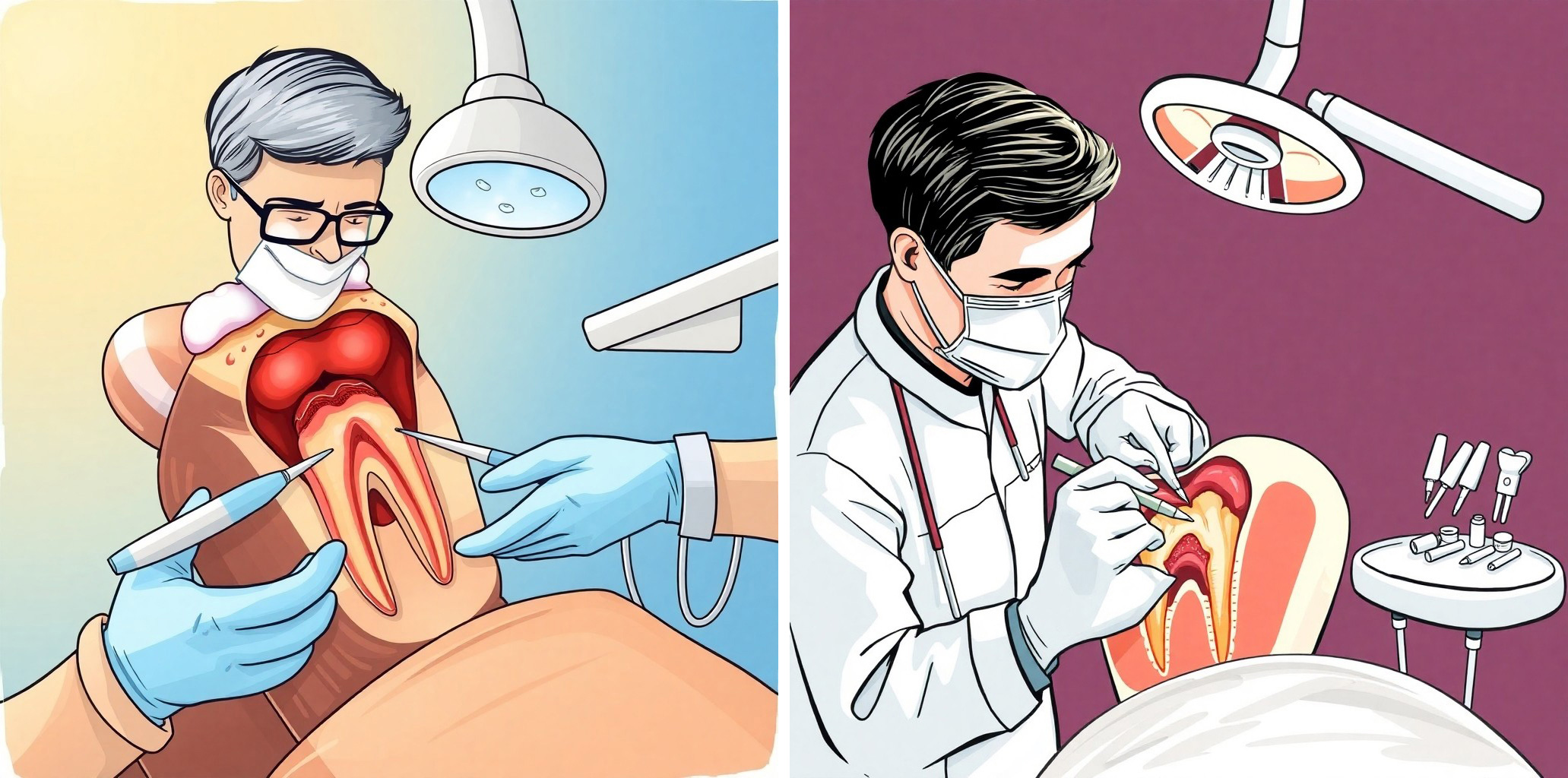
Figur 4A og B. To illustrasjoner lager av KI basert på oppfordringen «tegn en tannlege som utfører en rotbehandling». (Imagine)
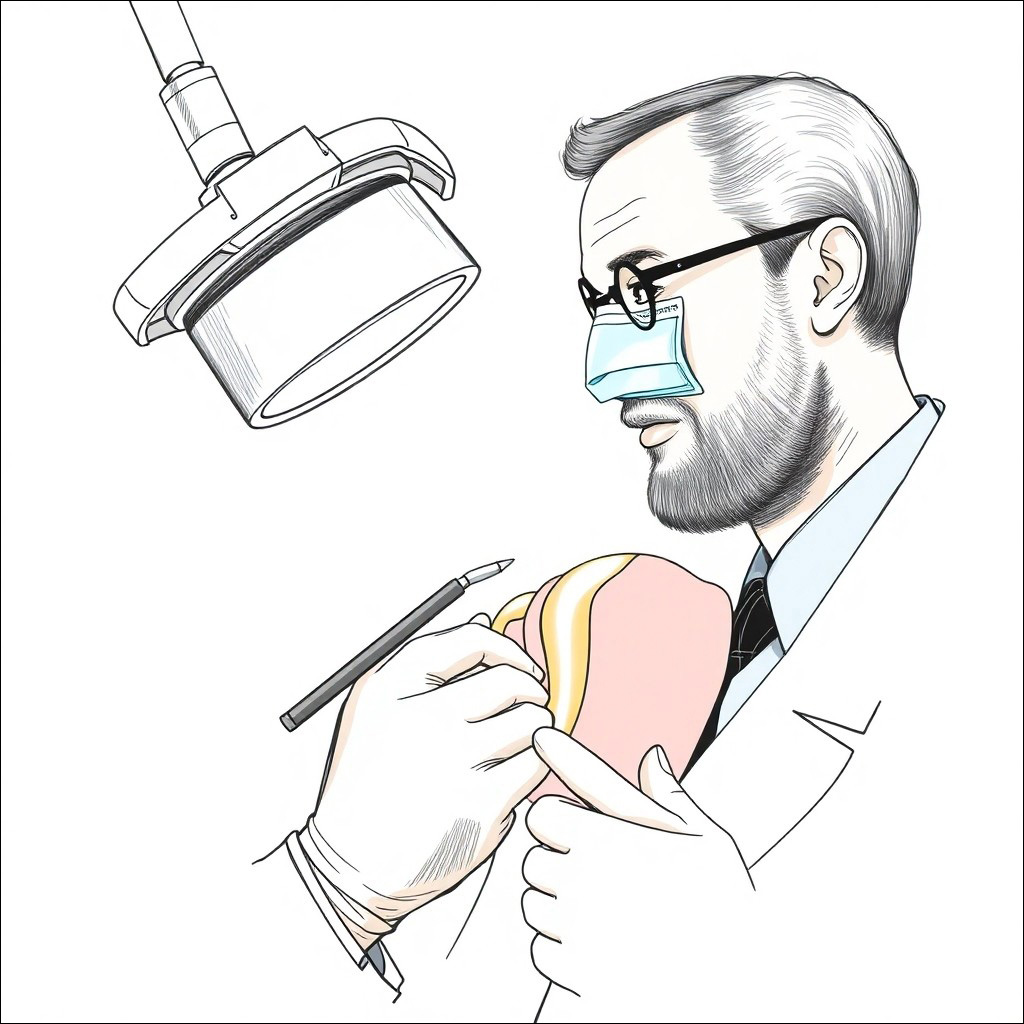
Figur 5. Illustrasjonen er laget etter en oppfordring «tegn en professor som utfører rotbehandling». (Imagine).
Det finnes svært mange betalingsbaserte KI-baserte tegne- eller bildegenereringsprogrammer som er mye bedre og som kan gi bilder og illustrasjonen som er naturtro eller feilfrie. Dette er også avhengig av hvor god man er på å skrive en god beskrivelse av hva man vil ha. Det er likevel verd å merke seg at tannlegen og professoren er en hvit mann i alle våre resultater. Det har vært mye kritikk om at KI-programmer diskriminerer. Kjønnsskjevheter er et spesielt gjennomgående problem i landskapet til LLM, som ofte forsterker stereotypier innebygd i de underliggende dataene. Dette kan sees i ordinnleiringer, en prosess der ord blir representert av hvor semantisk like de er [*]. Fordi KI som regel er trent på engelskspråklige kilder produsert i den vestlige verden og valgt ut av unge vestlige dataingeniører, gir utdataene ofte et skjevt bilde av verden og kan dermed underbygge stereotyper og gamle fordommer For eksempel vil setningen «Min kjæreste er lege», som regel oversettes til «My boyfriend is a doctor», mens setningen «Min kjæreste er sykepleier», oversettes til «My girlfriend is a nurse».
KIs tendens til å generalisere sykdomsmønstre og prevalens kan bli er stort problem når disse brukes i det medisinske feltet for diagnostisering og behandling. KI-algoritmer kan variere i ytelse på tvers av demografiske grupper, spesielt i grupper som er underrepresentert eller feilrepresentert i opplæringsdatasett. Flere kilder til skjevhet kan kulminere i KI-algoritmeskjevhet, definert som systematiske og gjentatte feil som gir urettferdige resultater og kan forsterke eksisterende ulikheter i helsevesenet. Disse typer skjevheter kan oppstå på ethvert trinn i KI-algoritmeutviklingen eller implementeringsprosessen og resultere i helseulikheter eller diskriminering i helsevesenet [*].
KI bør ikke forveksles med ML. KI er det overordnede konseptet for å skape intelligente systemer, mens ML er en spesifikk metode innen KI som hjelper systemer med å lære og ta beslutninger basert på data. ML er en underkategori av KI som fokuserer på å utvikle algoritmer som gjør det mulig for systemer å lære av data og forbedre ytelsen over tid uten å bli eksplisitt programmert. Målet er å gjøre systemer i stand til å lære og tilpasse seg autonomt basert på data. Eksempler er søppelpostfiltrering i e-post, prediktiv analyse innen helse, tolkning av røntgenbilder og annet.
KI-modeller blir kraftigere med mer data – men det er en grense for hvor mye data av høy kvalitet som finnes. AI forventes nå å gå tom for treningsdata om omtrent tre år, rundt 2028. Samtidig strammer dataeiere, som avisutgivere, inn på hvordan innholdet deres kan brukes, noe som begrenser tilgangen ytterligere [*]. Selv om det er usannsynlig at AI fullstendig vil "gå tom" for treningsdata, vil tilgangen på varierte og høykvalitets datasett bli en utfordring. I fremtiden kan økt bruk av lavkvalitets eller syntetiske data føre til AI-tilbakemeldingsløkker, noe som gradvis kan svekke både nøyaktighet og kreativitet.
Tannlegeutdanning
Hvor trekker vi grensen for bruk av KI i tannlegeutdanningen. Slik det er nå, er ikke tannlegestudenter så godt kjent med bruken. Noen studenter kan imidlertid være flinkere enn andre studenter og ha god nytte av hjelpemidlene. Videre kommer fremtidige studenter til å være godt kjent med bruk av KI. Hvordan skal vi forholde oss til lærere som kanskje ikke er godt bevandret som sine studenter.
KI kan i prinsippet skrive en masteroppgave, med referanser og det hele. Om disse er korrekte eller hallusinerte eller bare populærvitenskapelige tidsskrifter, må kontrolleres. Ulempen med dette er selvfølgelig at studenten får svært begrenset læringsutbytte og hele poenget med masteroppgaven faller bort. Muntlig eksaminasjon av masterprosjektet kan motvirke dette til en viss grad, men det krever mer ressurser til sensur. På den andre siden kan KI benyttes som hjelpemiddel og beslutningstøtte ved sensurering. Det kan også benyttes til å lage utkast til tilbakemeldingstekster som studentene kan få etter både formative (underveis-) og summative (slutt-) vurderinger. Dette vil være et godt hjelpemiddel for både undervisere og studenter. Det er viktig at dette gjører riktig og forsvarlig slik at personvern og rettsikkerheten til studentene ivaretas.
KI kan også skrive et forslag til et forskningsprosjekt. Du kan be ChatGPT om å designe et forskningsprosjekt du ønsker ved å skrive det du ønsker å studere. Be for eksempel om «design en outcome studie om revisjonsbehandling i endodonti». Du kan spørre hvilke metoder du kan bruke for å studere ulike egenskaper mellom to materialer. Den kan også lage utkast til en artikkel eller forbedre teksten. (Det er ikke KI som har skrevet denne teksten!). Chatte programmene kan også benyttes til studiestøtte på mange ulike måter, som diskusjonspartner, til å forklare komplekse problemstillinger, til å lage øvingsoppgaver før eksamen. Bare fantasien setter begrensinger her. KI være med på å utjevne forskjeller mellom de som er gode og dårlige i skriftlige norsk, men ulik datakompetanse kan derimot bidra til økte forskjeller på andre måter.
Det er imidlertid en rekke risikoer forbundet med KI. Fordi ingen riktig vet hva som skjer når KI skaper sine svar eller produkter, er det vanskelig å etterprøve disse og man risikerer at man tar beslutninger på feilaktig grunnlag (black box problematikk). Om man belager seg på at KI skal lage en oppsummering av artikler eller lærebøker for å sette seg inn i et nytt fagfelt, risikerer man å ikke forstå alt som ligger til grunn for kunnskapen. Dette gir bare en overfladisk innsikt og sjelden varig kunnskap. Dette er spesielt uheldig for studenter.
Det er viktig å merke seg at det er store forskjeller i amerikanske og skandinaviske verdier, regelverk og prosedyrer innen odontologi. På spørsmålet «What type of filling material is best suited for a decayed molar?” kommer amalgam opp som første alternativ selv når spørsmålet stilles på norsk.
Studenter trenger både opplæring og gode retningslinjer for bruk av generativ KI, slik at de kan bruke det riktig. En student eller forsker er ansvarlig for det de leverer eller publiserer. De må selv være klar over begrensningene, inkludert skjevheter og unøyaktigheter, ved verktøyene de bruker. Dette er et stort ansvar.
Konklusjon
KI kan, brukt riktig, gjøre oss mer effektive og presise. Brukt feil, kan de gjøre oss både dummere og mer upålitelige og bidra til opprettholdelse av diskriminerende holdninger og praksis. KI kan bidra til å løse mange oppgaver som i dag stjeler mye av vår tid, men som ikke egentlig krever human intelligens. Det kan effektivisere arbeidsoppgavene våre, lage referater, rapportutkast og administrere oppgaver. Det kan brukes til å oppsummere artikler og lage en kunnskapsinnhenting også fra vitenskapelige kilder. Man kan få hjelp til å lage et forslag til oppsett eller formuleringer på en oppgave eller artikkel, språkvask og oversettelser. Man kan også få hjelp til mer hverdagslige formål som reiseplaner, treningsopplegg eller en plan for å lese til eksamen og til å unngå prokrastinering.
Avslutningsvis er mulighetene for å bruke KI opp til fantasien vår. Her er et dikt basert på oppfordringen "Write a poem about Endodontics" og så "translate to Norwegian"
I den mørke hulen, en tann står svak,
Med smerte som en kvelende jakk.
Men frykt ei, for endodontisten er nær,
Med visdom og styrke, fjerner de sår.
Gjennom kanalenes labyrint de går,
Med filer og sonder, de utforsker og når.
I rotenes dyp, et mikroskopisk land,
Der hemmeligheter vever, i et tannlegesand.
Med kunst og vitenskap, de leger sårt,
Fra rot til krone, de helbreder med hårt.
Endodonti, en kraft av renhet og flid,
Gjenoppretter smil, i livets blide skjær.
Så la oss takke disse mestre i tann,
Som gir oss glede, der smerten forsvann.
For i endodontiens verden, finner vi fred,
Der tenners helse blomstrer, uten smerteled.
Referanser
Ethan Mollick. 2024. Co-intelligence: Living and Working with AI. Portfolio/Penguin; ISBN: 9780593716717.
Goodwin, M. KI-skole: Hvordan kunstig intelligens kan forenkle hverdagen. Kronos. Publiser 12.02.2025 (siste besøk 19.3.2025)
Hvorfor blir ikke alltid rotfylling vellykket? - Institutt for klinisk odontologi (uio.no). Aktuelle forskningssaker 2021. Siste besøk 19.3.2025.
Når bør rotfyllingen revideres? | Den norske tannlegeforenings Tidende (tannlegetidende.no). Siste besøk 19.3.2025.
Dental_Update_2004._Root_Canal_Retreatment._1._Case_Assessment_and_ Treatment_Planning.pdf (exodontia.info). Siste besøk 19.3.2025.
Dental Update - Theoretical considerations for root canal re-treatment (dental-update.co.uk). Siste besøk 19.3.2025.
Bolukbasi, T. et al. Preprint at arXiv https://doi.org/10.48550/arXiv.1607.06520 (2016).
Cho, M.K. Rising to the challenge of bias in health care AI. Nat Med 27, 2079–2081 (2021). https://doi.org/10.1038/s41591-021-01577-2. https://www.nature.com/articles/s41591-021-01577-2
Jones N, Thompson B. The AI revolution is running out of data. What can researchers do? Nature. 2025 Jan 31. doi: 10.1038/d41586-025-00288-9. PMID: 39890906.